Data Description
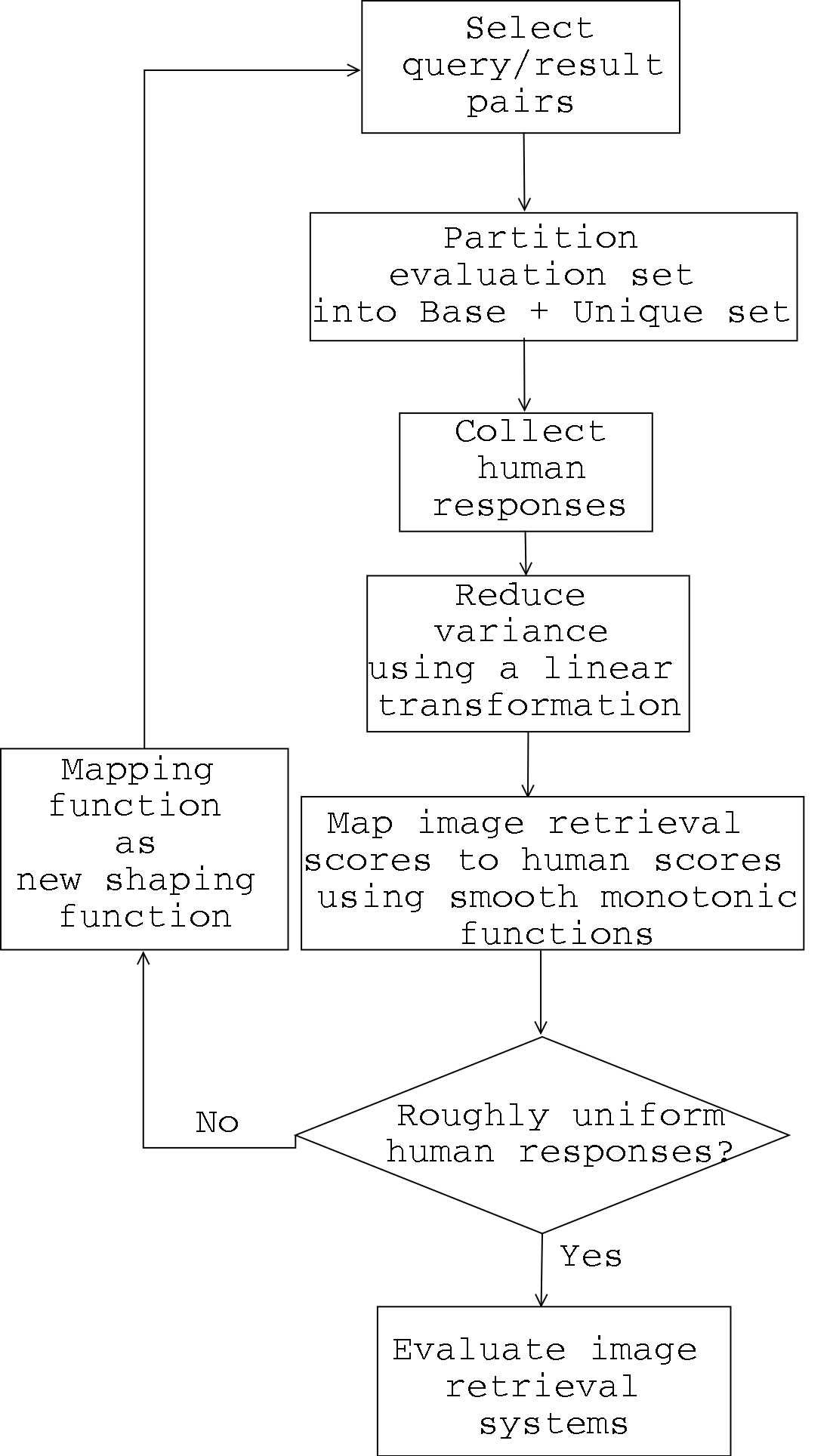
The groundtruth data (henceforth referred to as data) consists of human evaluation scores for a pair of query-result images. The pre-processing step involved selection of the query-result pairs such that they span the broad spectrum of choices i.e colloquially speaking from a good match to a poor match. We cannot choose query/result images at random as most of them will be judged as a poor match, hence resulting in a poor data. The main stratergy is to use existing image retrieval systems to select serviceable image pairs. Initially we do not know the input-output relationship that exists between the human scores and the computer scores. Hence, we propose an iterative approach to obtain a servicable range of images.The data consists of query-result pairs from four content-based image retrieval systems. This setup is conformed so as to be cautious about not introducing abnormalities in the data because of irregularities of certain image retrieval systems.

The experimental routine was as follows: First, the query image and result images from the four CBIR systems were displayed in random order. Then the user rated each match on a scale of 1 to 5 with 1 being a poor match and 5 a good match. We maintain the first 100 queries as common to all users so as to reduce the variance among evaluators. The rest of the images evaluated by the users, are unique. To get a common domain of scores, we mapped the computer scores to the adjusted human scores by three mapping methods. The mapping method the yielded the best correlation was retained. The agreement between the mapped scores and the adjusted human scores gave a indication of performance. Also, the data gives us options to measure precision-recall and normalized-rank.
Our algorithm is illustrated below:
In order to allow researches use our data we have made available the groundtruth data freely downloadable. We are also distributing the raw human scores. The format of this is as follows:
| user # | query image | result image | user score |
| user 1 | 1020018 | 1020019 | 3 |
| user 1 | 110006 | 870016 | 1 |
| . | . | . | . |
| . | . | . | . |
| user 2 | 1020018 | 1020019 | 2 |
| user 2 | 110006 | 870016. | 2 |
| . | . | . | . |
| user 3 | . | . | . |
| . | . | . | . |
Download
We provide two options:- Download the entire data with README files as a single tar [ Click Here]
- Browse the directory [ Click Here]
We believe that this data is not only ging to be useful to calibrate image retrieval systems but it would also aid in giving quantitative evaluations of computer vision algorithms. We encourage the computer vision community to use this data for their research. For choice of performances indices, you could refer our paper for the ones we have used or you could come up with your own. The database we use in our research was provided by Corel. This database has copyright restrictions and may not be freely distributed. But for those researches who have access to the Corel, our ground-truth data should simplify things because we use Corel's indexing scheme. We hope to develop a copyright free database in the future.