
[Work Log] Work Log
Memory leak in kjb_write_image
Found a memory leak in kjb_write_image.
...
convert_image_file_from_raster -> kjb_system -> create_system_command_process -> kjb_fork
Clustering with centered data
Modified inprogres/process_treatment_dates.m to log-transforms and normalize data. Re-ran clustering. Some observations:
First, noise standard deviation dropped from 25 to 17. The change is surprisingly subtle, considering we significantly reduced the dynamic range of the data. I should probably investigate this more...
Second, observation offset was on the order of 1e5. Should be near zero. Definitely investigate this more.
Centering did seem to fix cluster collapse, and the memberships were a bit more evenly distributed:

Investigating large observation offset.
Run 1: force offset to zero. does noise variance decrease?
Result: RMS error increased from ~17 to ~19.
looks like a bug in preprocessing
Found bugs:
- was normalizing on all data, not on rows.
- was dividing by mean (i.e. 0) not standard deviation.
preprocessed data looks much better now.
New bug: not enabling missing data. Fixing and rerunning...
...
RMS error is down to 0.4 for global regression model. Results for line-fitting in three regions is shown below (blue=before, green=during, red=after)
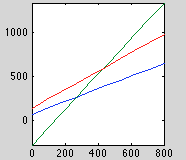
This seems in the ballpark. Full results below
0.00000000e+00 0.00000000e+00
7.22085911e-01 2.02331116e+00 1.04881185e+00
7.22916954e+01 -2.79730868e+02 1.41688548e+02
-2.56235739e-04 4.05002380e-04 1.79111799e-03 6.25535845e-04 -6.55416611e-04 8.34133235e-05 1.67634110e-03
2.49784115e-01 6.06155787e-01 -1.52977199e+00 1.15511031e+00 6.25982470e-01 4.20970189e-01 -5.78777462e-01
0.473467
Note that observation offset (5th line) is nonzero, even though we centered it. That's because this is the offset for the regression model, which is able to reveal more structure by taking time into account. This explains the lower-than-one standard deviation (6th line). The observation scaling (4th line) is interesting -- IFN-g and IL-8 are negataed, and TNF-a is tiny. Largest apparent activity in IL-1B and IL-2. I'm guessing this could change significantly once we start sampling the observation parameters.
Clustering results
K-means converges after 6 iterations.
Cluster memberships:

Only two strong clusters, despite using a three-cluster model.
Full results:
Observation (global):
A: -2.56235739e-04 4.05002380e-04 1.79111799e-03 6.25535845e-04 -6.55416611e-04 8.34133235e-05 1.67634110e-03
B: 2.49784115e-01 6.06155787e-01 -1.52977199e+00 1.15511031e+00 6.25982470e-01 4.20970189e-01 -5.78777462e-01
eps: 0.473467
cluster #1
m: 7.72956909e-01 2.23224762e+00 8.57568833e-01
b: 4.86565183e+01 -3.35063295e+02 3.15151426e+02
cluster #2
m: 9.18374118e+00 0.00000000e+00 0.00000000e+00
b: -5.45940758e+02 0.00000000e+00 0.00000000e+00
cluster #3
m: -3.69070988e+00 -3.02755277e+00 1.64214653e+00
b: 2.82195009e+02 3.96896877e+02 -2.56559679e+02
Discussion
Cluster 2 (the trivial cluster) seems to only have ata for the first region, which explains why it's ideosyncratic.
Clusters 1 and 3 differ dramatically in slope; cluster three drops significantly in the first two regions.
Do these clusters align closely with treatment type? (do tomorrow)
TODO
- Are cluster memberships linked to treatment type?
- matlab preprocess into struct, not file. then save struct to file
- use struct to visualize treatment type
- save cluster membership to file, visualize in matlab next to (2.)
- repeat k-means multiple times with random initializations.
- handle different treatment types.
- do full sampling.