
[Work Log]
June 13, 2013
After investigating the false positives from the last entry, it seems clear that bad matches look good because missing data are not penalized. For example
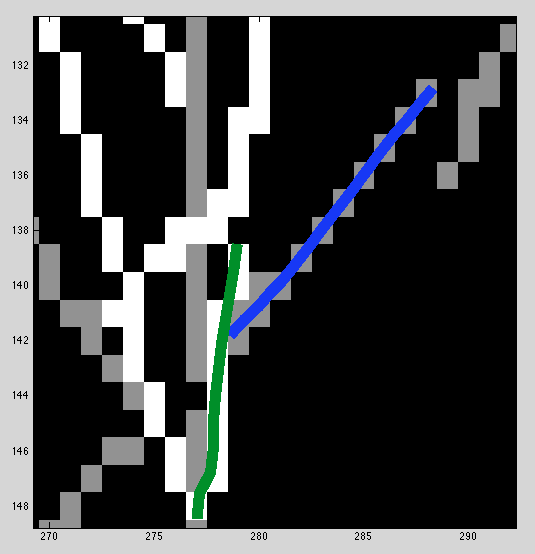
In the overlapping region of the blue and green curves, the distance between them is relatively low (less than 3 pixels, or 1.5px radius). But the size of their overlap is so low that it would be hard to claim that they come from the same underlying curve with any confidence.
Params
smoothing_variance_2d: 0.2500
noise_variance_2d: 10
position_mean_2d: [2x1 double]
position_variance_2d: 1.3629e+04
rate_variance_2d: 0.4962
smoothing_variance: 1.0000e-04
noise_variance: 10
position_mean: [3x1 double]
position_variance: 62500
rate_variance: 2.2500
smoothing_sigma: 0.2000
noise_variance_bg: 0.1038
I would have expected that noise_variance_bg was low enough to discount this candidate, but the log ML ratio is 71.0. The noise model must just look really bad...
Posted by Kyle Simek