The goal of this project is to learn stochastic geometric models of object categories from single view images. Our approach focuses on learning structure models that are expressible as spatially contiguous assemblage of blocks. The assemblages, or topologies, are learned across groups of images, with one or more such topologies linked to an object category (e.g. chairs). Fitting learned topologies to an image is useful for identifying an object class, as well as detail its geometry. The latter goes beyond just labeling objects, as it provides the geometric structure of particular instances.


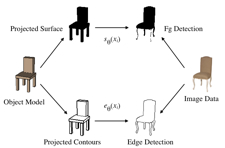
We learn the models using joint statistical inference over instance and category-level parameters. The instance parameters include the specific size and shape of an object in an image and its camera capturing the view. The category parameters encompass shared object topology and shape statistics. Together these produce an image likelihood for detected features through a generative, statistical imaging model (Figure 1). The category statistics additionally define a likelihood over structure and camera instance parameters (Figure 2).
For model inference and learning, we use trans-dimensional sampling to explore the varying dimensions of topology hypotheses. We further alternate between Metropolis-Hastings and stochastic dynamics to fit the instance and statistical category parameters. Figure 3 illustrates the learning process with a sequence of samples for two images in a set of tables; the instance parameters and shared category parameters are being inferred simultaneously.












Our experiments on images of furniture objects, such as tables and chairs, suggest that this is an effective approach for learning models that encode simple representations of category geometry and their statistics. We have also shown the learned models support inferring both category and geometry on held out single view images. Figure 4 shows some example results for learned models of tables, chairs, footstools, sofas and desks.
This work is published in NIPS 2009 and the software is available for download We are currently working on substantial extensions in a technical report that will ultimately be a journal submission. Comments are welcome, please send me an email.





































