
[Work Log] Work Log
Upon weaking the likelihood variance, we get this:
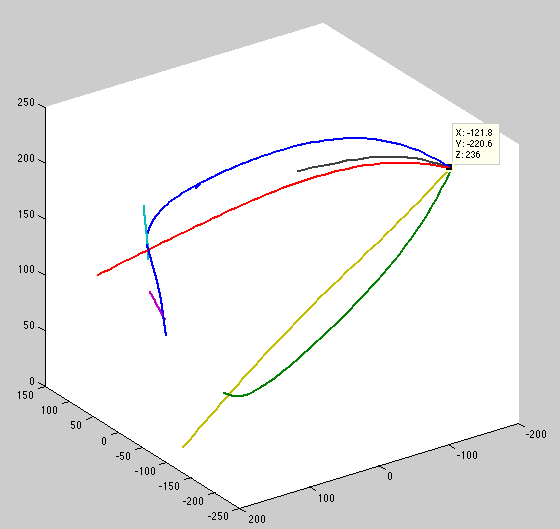
The bug is now clear: the independent curves (blue, red, yellow, green), are treated as attached at their root point. This is due to how the offset prior is handled -- the same offset variance is added to all curves, even the cross-covariance between independent trees.. Modified to measure the hamming distance between curves. If greater than zero, it receives the constant covariance.
The maximum posterior after fixing:
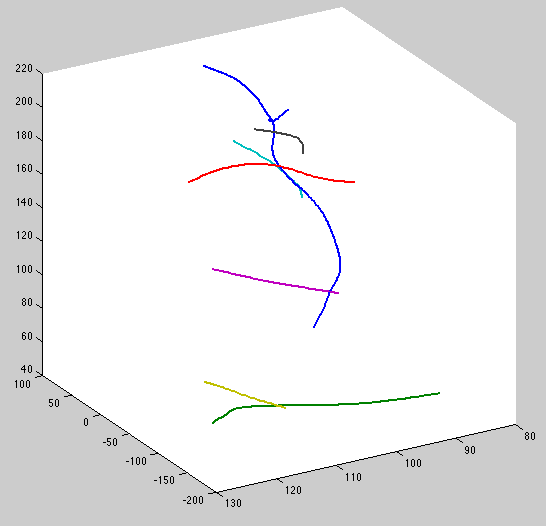
Compare to maximum likelihood:
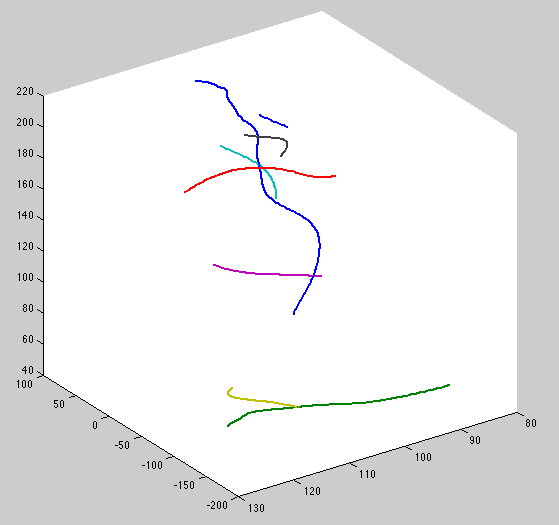
Notice max posterior is smoother and blue, magenta and cyan curves are attached to the blue parent. This is with zero temporal perturbation.
This explains the bad results yesterday; we should now be able to expoeriment with fancier priors.
Adding temporal perturbation
At temporal scale = 9, we get drift toward camera:
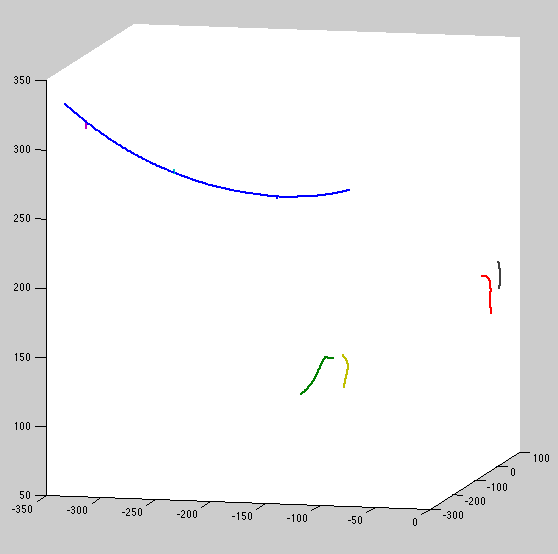
At scale 10, 100, 1000, still bad. It isn't until we get to scale=10,000 that we start to approach the results above (which used arbitrarilly large scale = 1e10)
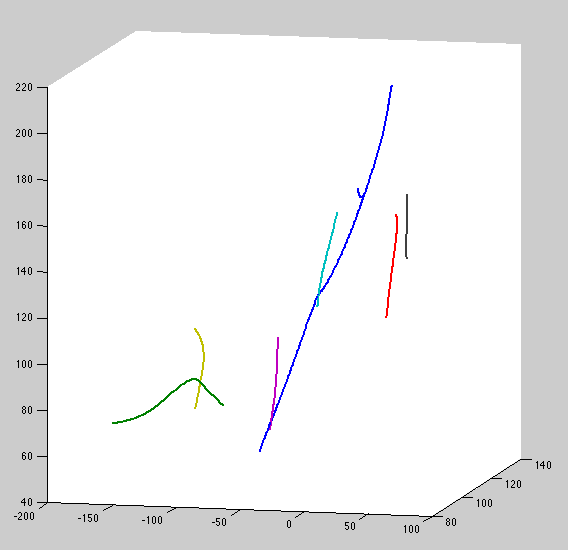
One downside of using a nonstationary covariance is apparent here: large blue curve is reversed in direction; its top is forced to be near-stationary, while the tip can drift quite far. During inference, we'll have to try both directions and keep the better. A stationary covariance function won't have this problem, should consider.
Wait -- setting all elements of perturbation covariance to zero should have no affect... Found bug in constructing prior covariance matrix. Fixed.
Now, adding the smallest amount of perturbation variance results in something like this:
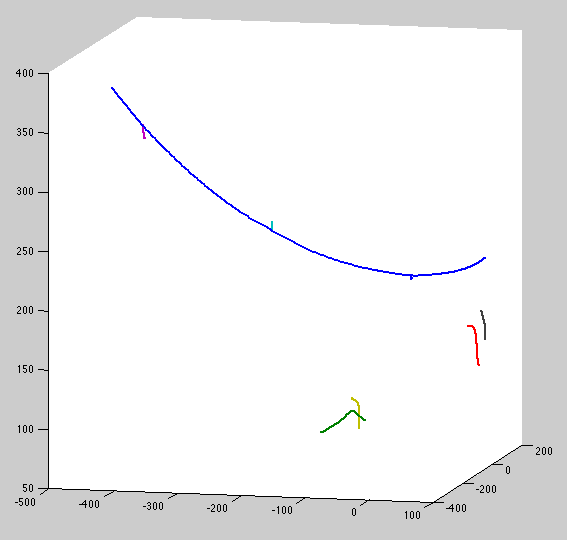
The problem here is fundamental to the cubic spline covariance: it can accellerate slowly but constantly until it's dramatically longer than its undeformed shape. Possible solution: prevent perturbations toward camera.
Getting reversed triangulation.
Due to reversed camera direction? (is negating camera valid here?)
When testing new camera direction, lost curves from view2. In rebuilding, realized our method for tracking curves was flawed -- it assumed optimization should start from the previous tree, but it should start at the mean of the perturbation prior distribution.
Also, the pattern-search method seems to be failing to find a good second view. Implemented quasi-newton method to test against the pattern-search method.
To test:
- quasi-newton perturbation search
- new approach to initializing optimization
- reversed cameras
- maximum posterior curves (naive method)
- maximum posterior curves (kalman filter method)