
[Reference] Articulated gaussian processes (part 2)
Continued from part 1.
Covariance functions
Recall the 1D cubic-spline covariance:
We can generalize this to ND indices as
When using a cubic-spline covariance function, the only dimensions that are nonzero are those corresponding to shared ancestors. The position along the curve only matters when comparing points on the same subgraph. For trees, this exactly corresponds to the branching Gaussian process covariance I derived in my dissertation proposal. Plate regions act like thin-plate splines.
When using a radial-basis covariance function like squared exponential, the squared L2 distance has a nice interpretation. Take any path between two nodes, and split it at articulation points into a sequence of subpaths. The squared L2 distance is the sum of the squared local distances between articulation points, plus the squared distance between the endpoints and their nearest articulation points. This is similar to the squared geodesic distance between the points, but modified to restart the distance measurement from zero at each articulation point.
Generalizations
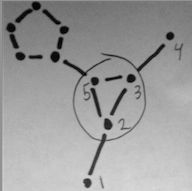
It may be interesting to model plates as being superimposed on an underlying chain. For example, in the image above, 1,2,3,4 is probably well modelled by a smooth curve (i.e. a single chain), but 2,3,5 is also clearly a plate. We might want to let point 5's position influence points 2 and 3, without violating smoothness of 1,2,3,4. To handle this, we relax the requirement that the plate and chain must lie in orthogonal hyperplanes. We modify equation (1) so instead of vertex 5 inheriting the index of its predecessor (e.g. vertex 3), we replace the first term with the linear interpolation between indexes 3 and 4. This lets subgraph 2,3,5 act a little bit like a chain and a little bit like a plate. How to implement this linear interpolation is up for debate, but two possibilities are: (a) relative euclidean distance, or (b) relative geodesic distance.
Altnerative definition
The definition of the index-space below is equivalent to the one above, but requires some extra proofs to explain (like proving all DFS paths between vertices within a subgraph are fully contained within the subgraph). It was just too cumbersome, rhetorically, but quite convenient to implmement. I'm including it here so I remember it during implementation.
...
For each vertex vi∈V, we assign an index xi∈R|Gc|+2|Gp|. We arbitrarilly pick a vertex v0 to be the graph's root, and set its index to x0=0. For each vertex vi∈V∖v0, let p(i) be the index of its predecessor in a depth-first search. We then define the index of vi to be
where d:V2→R|Gc|+2|Gp| is the concatenation of displacement functions, i.e. d(v,v′)=(dc1(v,v′),dc2(v,v′),…,dp1(v,v′),dp2(v,v′),…).
Posted by Kyle Simek