
[Work Log] Index optimization, end-to-end
Troubleshooting ML optimization.
Found a few bugs in the optimization code.
- math bug in variable transformation formula. Applying chain rule to account for transformation used wrong formula.
- math bug in new version of gradient function. Used Uc where Uc' was called for (transpose of cholesky)
As a result of bug #2, decided to re-implement end-to-end test (which hadn't been run for some time; was running a unit test on synthetic data). Refactored test to use the functional style in test/test_ml_deriv.m, added hessian computation.
Fixed gradient looks good. Hessian is way off.
found some bugs in hessian
- forgot to include terms from linear covariance function.
- forgot to scale second derivitives by variance parameters.
- used H1 + H2 instead of H1 - H2
All of these weren't caught in the unit test, because everything was tested in isolation, with scaling constants omitted.
Looks a lot better now, still some error on the order of 1e-2. Most troubling isn't the magnitude, but the fact that the error seems to be structured, as opposed to random:

We're comparing against numerical approximation, so the error might be in the approximation, not in the math. For now we'll proceed, but there's probably room for further investigation in the future.
Ran index optimization, and results for curve #10 are much improved. Curve #7 still overshoots, but beyond that, no significant nastiness.
Initially, we were getting errors from the gradient checker. Swtiching the central differences fixed it.
Interestingly, the optimization algorithm takes 10X to 30x more iterations to complete. (update: Hessian isn't being transformed correctly)
Recall that we increased the position-perturb variance significantly. This seems to improve ground-truth reconstructions; setting it too small causes bizarre curves and over-extensions. Below, we see the old method, followed by the new method with large position perturbation variance, and the new method with small perturbation variance.
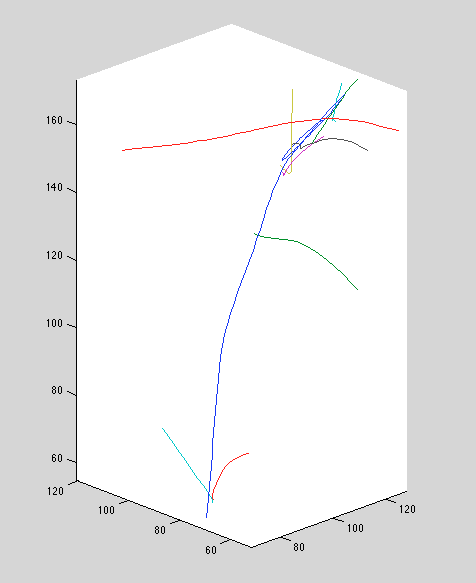
Above: old method
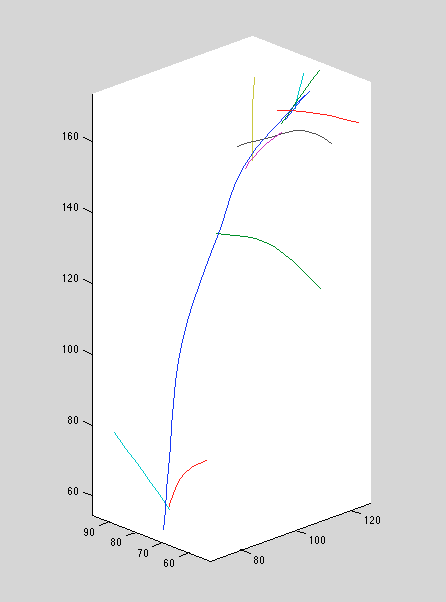
Above: new method, large position perturbation variance
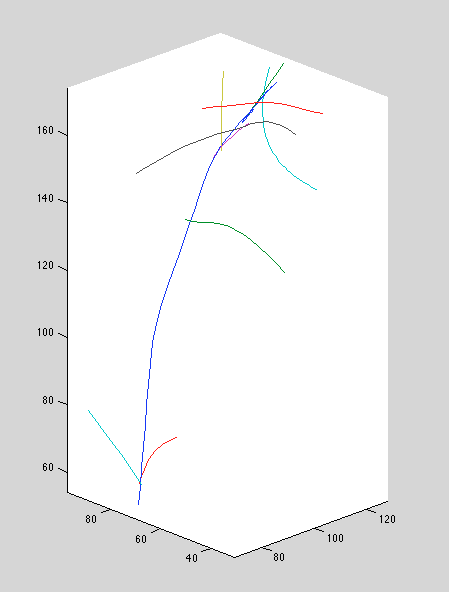
Above: new method, small position perturbation variance
Tried fixing hessian, results are worse. Probably got the transformation math wrong.
TODO
- per-view ordering constraints
- fix hessian transformation
- investigate curve #7
- possibly larger position perturbation variance will help?
- maybe fixing hessian will help?