
[Work Log] Work summary
Finished editing new likelihood function. See correspondence/clean_correspondence3.m (filename likely to change soon). Below is a summary of results and comparison to the old approach.
Results
Below is a plot of the maximum likelihood curves:
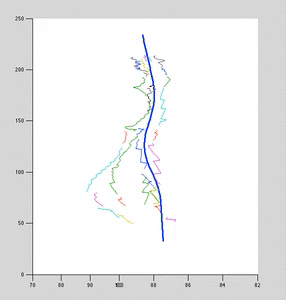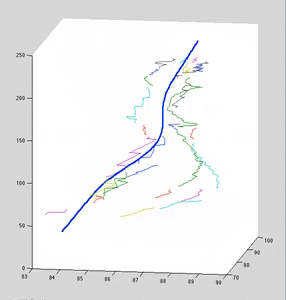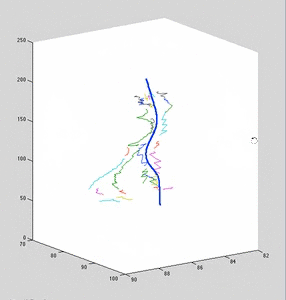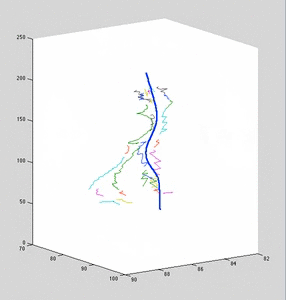
Each colored curve arises from a single 2D data curve. The curve represents the mean of a gaussian process. Variance is not shown; it is infinite in the direction of backprojection.
The dark-blue curve is an estimate of the posterior curve, which was used to backproject the 2D curves against. It is estimated from the point-correspondences.
Note that for clarity, x/y scale is significantly smaller than z-scale (up-direction). When axis are equally-scaled, max-likelihood curves lie very close the to blue curve.
Improved correspondence
The old likelihood suffered from a small but non-negligible number of awful correspondences, which severely damaged both reconstruction and marginal likelihood values. This was because the likelihood was derived from the point-to-point correspondences, which (a) is problematic at gaps, and (b) suffer bad correspondences which can't be fixed later. The new approach uses the old approach as a starting point, but then recomputes all 2D curve correspondences against a rough reconstruction. This dramatically improves correspondences as we see below.
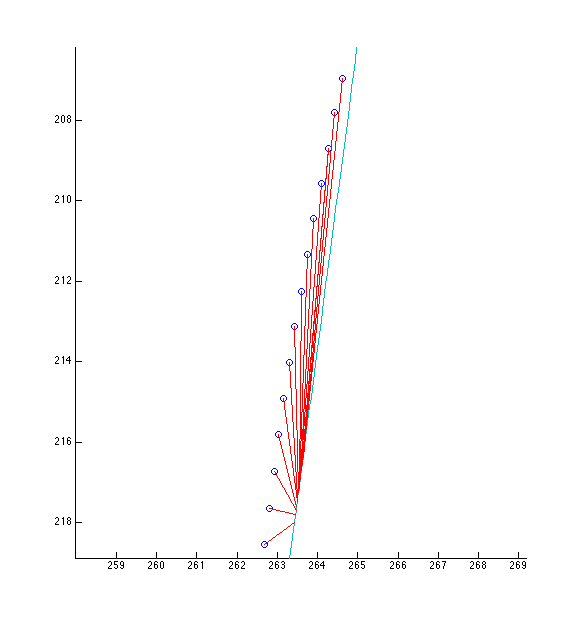
This is the old correspondence. Blue points are points from the 2D data curve; the teal line is the posterior 3D curve (projected to 2D); red lines show correspondences.
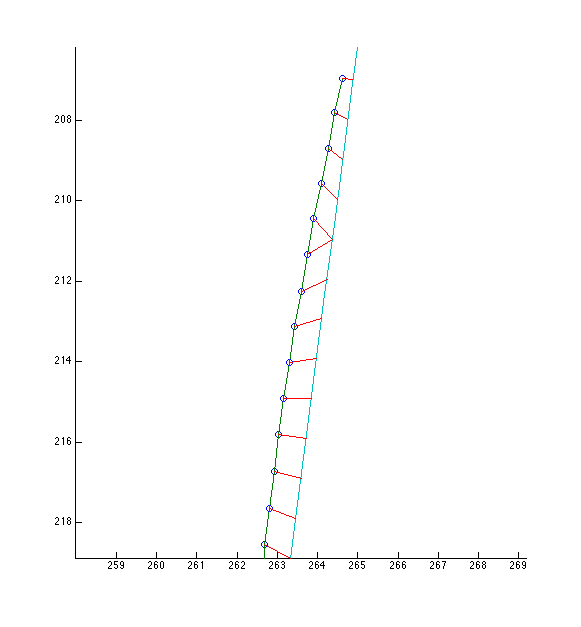
Next is the fixed correspondence. Notice how the red correspondence lines are much shorter, indicating a less costly correspondence.
Per-data-curve likelihood
The old likelihood had a single GP curve that represented all of the different views. Now we have a GP curve per data-curve, which will be related by a GP prior.
This will allow us to simultaneously track and triangulate, a key novelty to this approach. More importantly, it will give us higher marginal likelihood numbers for true 3D curve observations, because we can make the independent noise component very small.
TODO - short-term
- Optimization - This new function adds an extra pass of DTW per data-curve, per iteration where previously, only one pass was needed. This has introduced a significant performance bottleneck on the order of 10-50x. I need to profile and optimize this function if we want runtimes that aren't measured in weeks. This may motivate a full re-thinking of
merge_correspondence.m, to avoid a full DTW after every merge. - Marginal Likelhood - Need to build the new marginal likelihood for the foreground curve model. This proposed version will take advantage of the new per-data-curve likelihood.
TODO - mid-term
- End-to-end - Incorporate new likelhood and ML into gibbs sampler.
- Swendsen wang cuts - design SWC split/merge move