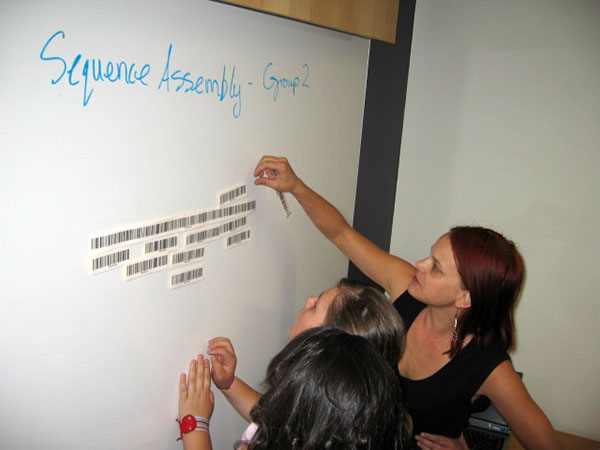IIS-0747511
|
IIS-0747511 |
|
This material is based upon work supported by the National Science Foundation under Grant No. 0747511. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.
This project will develop approaches for learning stochastic geometric models for object categories from image data. Good representations of object form that encode the variation in typical categories (e.g. cars) are needed for important problems in computer vision and intelligent systems. One key problem is object recognition at the category level. What makes an object a member of one category (e.g. tables) instead of another (e.g. chairs) strongly relates to its structure, and automatically choosing among them to robustly recognize a new object requires appropriate representations of form. A second problem is reasoning about object configuration and structure. For example, a standard chair should be recognizable as being similar to a table in certain ways, different in other ways, perhaps seen as blocking a particular path in a room, and considered useful as a step for reaching something. To achieve this level of understanding, representations for geometric structure that can link to physics and semantics are needed. But where should they come from? To address this question, this project will explore learning effective representations from image data. More specifically, this project will study the novel approach of putting representation at the core, and learn from data which objects can be modeled in this manner. The work will begin with simple effective representations that are appropriate for some objects, and then expand the pool of models, largely by exploiting the fact that many complex objects are composed of simpler, natural, substructures, and that these are shared across multiple object categories. One result of this process will be statistical models for objects based on image data that will be disseminated to the research community.
This research will have positive impact on many applications that rely on robust recognition and scene understanding from image data, particularly in cases where the configuration, orientation, and form of objects are relevant. These include applications where robots must function in natural environments and systems for augmenting human operators in numerous industrial, military, and everyday situations. The learned object category representations will have additional uses in image and video retrieval and for model palettes in computer graphics applications. This research will also impact biomedical research by improving automated extraction of biological structure from image data to recognize phenotypes and to quantify the relation of form and function in high throughput experiments.
This project integrates two important educational initiatives: 1) curriculum development to increase opportunities for classroom study in computer vision, machine learning, and scientific applications at the University of Arizona; and 2) an educational outreach program targeted at Tucson high-school students from low socioeconomic groups that will promote an understanding of the integration of science and computation.
The image to the right shows a simple model for chairs learned from a modest set
of 2D images using the representation of a collection of connected blocks and
the key assumption that the topology is consistent across the
object category. The particular instances that are fit collaterally are shown in
red. For the category we learn the topology and the statistics of the block
parameters.
|



|
|||
We are also building system to automatically understand
scenes in geometric and semantic terms---what is where in 3D. Doing this from a
single 2D image involved inferring the parameters of the camera, which can be
done assuming a strong model. In this case we adopt the Manhattan world
assumption, namely that most long edges are parallel to three principle axes.
Different from other work, we develop a generative statistical model for scenes, and the objects within them.
|


|
|||
The image(*) to the right shows undergraduate Emily Hartley determining the
geometry of an indoor scene and the parameters of the camera that took the
picture of the scene. Such data is
critical for both training and validating systems that automatically infer scene
geometry, the camera parameters, the objects within the scene, and their
location and pose.
|

|
|||
Integration of Science and Computing
|
|